

I’m an accidental DBA, but I still never quite got the hate for ORMs. I thought this article does a good job explaining the issue, and why they aren’t so bad.
For me the article touches on the problem but doesn’t actually reveal it.
What I see day in and day out is projects using a relational database to store data that is not suited to a relational database. And you can often get away with that fundamental mistake when you’re writing raw SQL queries… but as soon as an ORM is involved you’re in for a world of pain (or at least, problems with performance).
I’d actually say most data is suited for relational DBs, and that was pretty much what people realized after a few years of the NOSQL hypetrain.
The article you linked disagrees - they said it pretty well:
Of course, some issues come from the fact that people are trying to use the Relational model where it doesn’t suit their use case. That’s why I prefer a document model instead of a tabular one as the default choice. Most of our applications are more suitable for it, as we’re still moving the regular physical world (so documents) into computers. (Read also more in General strategy for migrating relational data to document-based).
I never joined the NOSQL hype-train so I can’t comment on that. However I will point out storing documents on a disk is a very well established and proven approach… and it’s even how relational databases work under the hood. They generally persist data on the filesystem as documents.
Where I find relational data really falls over is at the conversion point between relational document representation. That typically happens multiple times in a single operation - for example when I hit the reply button on this comment (I assume, haven’t read the source code) this is what will happen:
- my reply will be sent to the server as a document, in body of a HTTP request
- beehaw’s server will convert that document into relational data (with a considerable performance penalty and large surface are for bugs)
- PostgreSQL is going to convert that relational data back into a document format and write it to the filesystem (more performance issues, more opportunities for bugs)
And every time the comment is loaded (or sent to other servers in the fediverse) that silly “document to relational to document” translation process is repeated over and over and over.
I’d argue it’s better, more efficient, to just store this comment as a document because over and over and over it’s going to be needed in that format and anyway you ultimately need to write it to disk as a document.
Yes - you should also have a relational index containing critical metadata in the document. The relationship linking that document to the comment that I replied to. The number of upvotes it has received. Etc Etc… but that should be a secondary database, not the primary one. Things like an individual upvote should also be a document, stored as a file on disk (in the format specified by AcitivtyStreams 2.0).
and it’s even how relational databases work under the hood. They generally persist data on the filesystem as documents.
I’m 99% certain this is wrong, which leads to a lot of your follow-up being wrong. Persisting data as documents would be atrocious for performance.
I also disagree with the quoted part of the article.
And for your case, sure, you could save it as document, maybe improve performance of a very light operation by 2X, just to have far worse performance for querying that data.
edit: And in case you don’t mind the extra storage, and don’t care about correctness guarantees, you can just have a table that has all the metadata, but then have the comment also as a JSON blob which every modern db supports.
I’m 99% certain this is wrong
? This is how Postgres stores data, as documents, on the local filesystem:
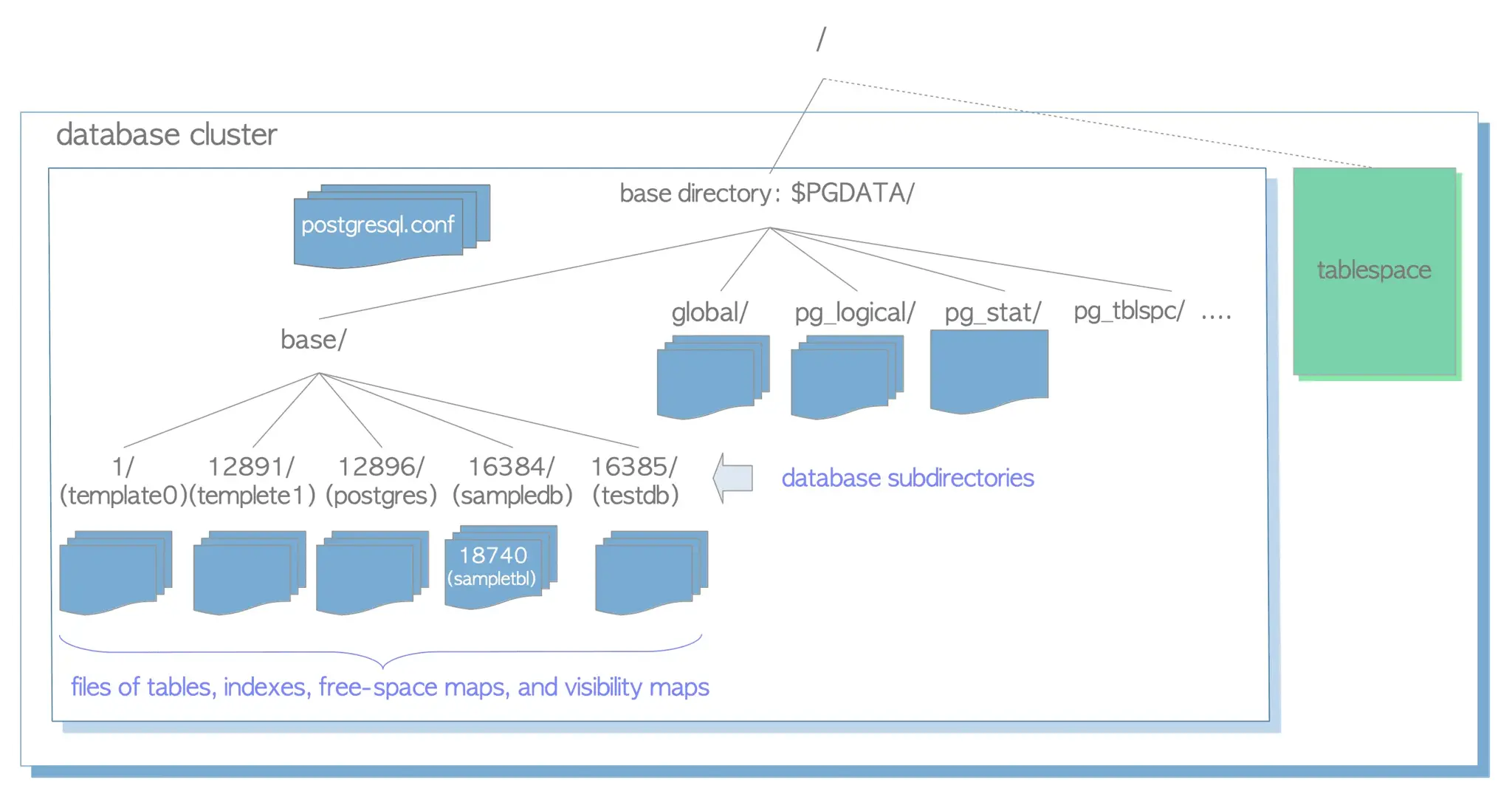
There are hundreds, even thousands, of documents in a typical Postgres database. And similar for other databases.
But anyway, the other side of the issue is more problematic. Converting relational data to, for example, a HTTP response.
Persisting data as documents would be atrocious for performance.
Yep… it’s pretty easy to write a query on a moderately large database that returns 1kb of data and takes five minutes to execute. You won’t have that issue if your 1kb is a simple file on disk. It’ll read in a millisecond.
I’m 99% certain this is wrong
? This is how Postgres stores data, as documents, on the local filesystem:
Those are not documents for a definition of document that works with the rest of your comment. If by document you mean “any kind of data structure”, then yes, those are documents. But then the term becomes meaningless, as literally anything is a document.
Yep… it’s pretty easy to write a query on a moderately large database that returns 1kb of data and takes five minutes to execute. You won’t have that issue if your 1kb is a simple file on disk. It’ll read in a millisecond.
Sure, but then finding that document takes 5 minutes because you need to read a few million files first.
If by document you mean “any kind of data structure”, then yes, those are documents
Yep — that is what I mean by documents, and it’s what I meant all along. The beauty of documents is how simple and flexible they are. Here’s a URL (or path), and here’s the contents of that URL. Done.
But then the term becomes meaningless, as literally anything is a document.
No, because you can’t store “literally anything” in a Postgres database. You can only store data that matches the structure of the database. And the structure is also limited, it has to be carefully designed or else it will fall over (e.g. if you put an index on this column, inserts will be too slow, if you don’t have an index on that column selects will be too slow, if you join these two tables the server will run out of memory, if you store these columns redundantly to avoid a join the server will run out of disk space…)
Sure, but then finding that document takes 5 minutes
Sure - you can absolutely screw up and design a system where you need to read millions of files to find the one you’re looking for, but because it’s so flexible you should be able to design something efficient easily.
I’m definitely not saying documents should be used for everything. But I am saying they should be used a lot more than they are now. It’s so easy to just write up the schema for a few tables and columns, hit migrate, and presto! You’ve got a data storage system that works well. Often it stops working well a year later when users have spent every day filling it with data.
What I’m advocating is stop, and think, should this be in a relational database or would a document work better? A document is always more work in the short term, you need to carefully design every step of the process… but in the long term it’s often less work.
Almost everything I work with these days is a hybrid - with a combination of relational and document storage. And often the data started in the relational database and had to be moved out because we couldn’t figure out how to make it performant with large data sets.
Also, I’m leaning more and more into using sqlite, with multiple relational databases instead of just a single database. Often I’m treating that database as a document. And I’m not alone, Sqlite is very widely used. Document storage is very widely used. They’re popular because they work and if you are never using them, then I’d suggest you’re probably compromising the quality of your software.
Yep — that is what I mean by documents, and it’s what I meant all along. The beauty of documents is how simple and flexible they are. Here’s a URL (or path), and here’s the contents of that URL. Done.
But that content is meaningless, because you just saved an arbitrary data structure. It’s not as if you can do anything with those postgres files. Or those possibly multi GB MSSQL
.mdf,.ldf,.ndfdocuments. That’s data (a word that’s imo far clearer than document) stored in a very specific way that you need to know the exact structure of to make any sense of. It’s not usable directly in any way. Not “Done.”No, because you can’t store “literally anything” in a Postgres database.
Yes you can. You can either add space for what you need to store, or you can, again, store e.g. a JSON blob.
if you put an index on this column, inserts will be too slow, if you don’t have an index on that column selects will be too slow
Or don’t, and it will only be as slow ass a NoSQL Database …
A document is always more work in the short term
It’s the opposite, a document db is far easier in the short term, that’s why everyone jumped on them before seeing the limitations.
Yeah, a relational DB is harder because you have to have a good design, that allows you to do what you actually want to do. And if you none of your devs are good at SQL, then probably a document db is better. And yes, sometimes, you need nothing but a document DB. But I still heavily disagree that most of the time you want one.
I’d argue it’s better, more efficient, to just store this comment as a document because over and over and over it’s going to be needed in that format and anyway you ultimately need to write it to disk as a document.
You’re assuming the file system overhead is smaller than the overhead of a database stored on the file system, and that’s a pretty bold statement.
The issue isn’t storage and retrieval, it’s search, it always has been. Your comment being a document or not isn’t the hard part or the expensive part. Associating your comment with the post, comments, and likes is where the hard parts come in.
Yeah, you could make every comment a document of sorts and store each one as a file and add an index that points to the files, but you’d be introducing a bunch of overhead caused by the file system.
It’s kind of a similar idea for why you don’t store a movie as a directory with a picture for each frame. You absolutely could, but there are very good reasons not to do so.
Database are just hyper optimized versions of “storing documents.” I think you’re severely overestimating the cost of moving a few bits around to change how data is represented.
As long as you never store the same data in two places, documents are fine. But if you’re gonna store my name along with my id on the post you’re describing, then forget it. Your entire life is pain from now on and you will not give a single shit about join efficiencies, or converting between docs and relational, or maybe even your family, pets or home.
Defense doesn’t have a c in it.
@Scary_le_Poo @cwagner it does in British English. American English is so weird.
You should send that information to the non-native English speaker that wrote the blog. Might as well go ahead and gather all the other typos he did.
And we have a picture of Back from the Future, why? :)
Hey Google, use a picture of someone defending someone from someone angry ;)
I much prefer the repository pattern, as used by sequel and Ecto
Your models are essentially just enhanced structs. They hold information about the shape of data. Generally don’t hold any validations or logic related to storing the data. You perform changes on the data using changesets, which handle validation and generating the transaction to persist the data
It works extremely well, and I’ve yet to encounter the funky problems ActiveRecord could give you
OK, but what about reading the data?
I’ve never had a problem writing to a database with an ORM. The problems happen when you try to read data (quickly and efficiently).
I agree, it’s even what I mostly use the ORM for, writing is so easy that way and results in far more succinct code.
Data comes out as a map or keyword list, which is then turned into the repository struct in question. If you want raw db data you can get that too. And you can have multiple structs that are backed by the same persistent dataset. It’s quite elegant.
Queries themselves are constructed using a language that is near SQL, but far more composable:
Repo.one(from p in Post, join: c in assoc(p, :comments), where: p.id == ^post_id)Queries themselves are composable
query = from u in User, where: u.age > 18 query = from u in query, select: u.nameAnd can be written in a keyword style, like the above examples, or a functional style, like the rest of elixir:
User |> where([u], u.age > 18) |> select([u], u.name)None of these “queries” will execute until you tell the Repo to do something. For that, you have commands like
Repo.allandRepo.one, the latter of which sticks alimit: 1on the end of the provided queryI wouldn’t call that “near” SQL, I’d basically just call it SQL. Nothing wrong with that… SQL is great, and using proper language constructs instead of strings makes it even better… but it’s not solving the some problem as an ORM.
True, however it occupies the same niche an ORM occupies, without the foot guns. Updating a slew of different db tables from rather clean and straightforward models is relatively simple. It tries to live somewhere between just doing everything as SQL and abstracting everything away like AR does, giving you conveniences from both approaches. You don’t get mired in scoping hell, but you don’t have big ugly messes of nearly-identical SQL statements either.
i’d recommend trying it out https://hexdocs.pm/ecto/Ecto.html




